

This time we have the Clojure enthusiast Mauricio Szabo in our Clojure Corner. He is currently working on Atom successor.
Ela Nazari: Well hello everyone, I’d like to thank Mauricio Szabo for accepting being guest of our Clojure Corner. Allow me to introduce Jiri Knesl the founder of Flexiana and Gustavo Valente our cool Clojurists who will run Corner this time.
Mauricio Szabo: Hi folks, I’m Maurício, thank you for inviting me!
Gustavo Valente: Fala Mauricio. I am Gustavo.
I know that you are writing an editor, but before that, can you tell us a little about you. Like, what is your background, and what was your journey before meeting Clojure?
Mauricio Szabo: Hola, Gustavo! Yes, I am writing an Editor (kinda – more on that later).
Ok, so my background is interesting – I say that my life starts to become more “random” the more I tell, but let’s start on that – I was born in Brazil, São Paulo, and for the last three years I’m living in Uruguay, Montevideo.
So, since my first computer (a 486-SX) I wanted to make software programs (which, at the time, I didn’t even know what it was – the term “programming” wasn’t even usual at the time, I just asked my mother how could I generate an .exe file ). A friend of mine was studying QBasic, and I basically self-learned how to write simple stuff, then more complex, up to the point I tried lots of languages – VisualBasic, Delphi, C/C++, Java, and I ended up in… Ruby. Which was amazing (at the time) and somehow felt it was closer to my though process (less abstractions, more “right to the point”, etc).
At the time, I heard a lot of people talking about LISP (including my teacher, who eventually became a good friend) and I wanted to try some LISP implementation. It was a disaster . I could not understand why people liked the language so much, and I spent a couple of years trying some LISP flavor, giving up, trying again, etc. Until I found LightTable, which seemed even closer to what I wanted to achieve (a good way to explore software programs without having to “play the computer” in my head). So I decided to try with Ruby, but quickly I migrated to Clojure because the experience was better.
LightTable was complicated and had few plug-ins (I tried to write some, for example, to integrate Parinfer on it) but ended up trying to replicate the LightTable experience in my editor of choice – Atom – with the plug-in called ProtoREPL. I found the experience so amazing that I ended up contributing to the project, then doing some extensions, and finally I migrated my stack to Clojure.
Jiri Knesl: Hi Mauricio, how are you?
Why do you think people migrate from Ruby to Clojure?
Mauricio Szabo: Wow, interesting question!
I migrated because I wanted to explore interactive programming – I used to say that I migrated from Ruby to LightTable, and Clojure just appeared because LT worked better with Clojure.
As for friends that I know, usually is because of Rails. It’s hard to use Ruby without it – not impossible, but hard. So if you need something different from “a web api rendering JSON / server side rendered web app” Rails shows its limitations. Because of the JVM, and because there’s no “one true framework” in Clojure I believe it’s easier to not have these problems.
So, it’s easy to bootstrap an webapp with Ruby and Rails, and harder with Clojure, but harder to modify a Ruby app when it starts to grow (and even harder to extract fragments to different services).
Jiri Knesl: You’re absolutely right with the fact it is often difficult to extract parts of Rails app into non-Rails code with monkey patching, Active Support, etc. When I interview candidates to Flexiana who are moving from Ruby to Clojure, it’s a common theme. You change something in one part of your app and it breaks elsewhere because of hidden relationships and conventions.
At the same time, some things can be done extremely productively in Rails, or even Sinatra. Devise gem, Turbo, Active Admin, and others can make development very fast. In Xiana, we are trying to close this gap. Have you seen our framework already?
Mauricio Szabo: projects that would never exist if it wasn’t for Rails, so there’s a balance here. As an example, I would probably not start a Clojure project if I knew all I had to do was a simple web page.
And unfortunately, no, I haven’t seen the Xiana framework. To be fair, I haven’t seen any framework in Clojure – most of the projects I worked with (including my personal ones) are a little unconventional so I don’t think a framework would help (in my case).
Probably the closest I got into frameworks in Clojure was to try to write my own as an exercise (literally, just an exercise) and the combination of re-frame and reagent in the ClojureScript side.
Gustavo Valente: Its looks like that “fate” bring you to Clojure, I mean if LightTable was in Smalltalk you still get your interactivity without Clojure.
But my question now is, what hooked you with Clojure? What do you like and dislike about it?
We know that Clojure is a niche programming language, what do you think is missing to Clojure gain more traction? I mean why do you think Clojure did not storm JVM world as it is more simple and easy to code with?
Mauricio Szabo: Well, kinda. I did try Smalltalk previously, but the language didn’t “click” with me. Maybe it’s because it felt “too different” or because everything had to be done in this different environment, with different tools, or maybe it’s because everything needs to be encapsulated all the time, who knows? I did try Smalltalk again recently (on the Advent of Code 2023) and again, it didn’t click with me (although I could solve some 2, 3 problems on it).
What hooked me in Clojure is how pragmatic the language is. I’m also very pragmatic (maybe even more than what’s considered “normal” or “sane” to be honest) so the whole “evaluate something, get the intermediate results on it, then iterate over it” was such an amazing feeling!
To the point it even broke my old TDD workflow . I had to re-train myself to write better tests, because I was starting to neglect my testing (I think I found a sweet spot now, but I’m studying a way to have an even sweeter spot with my plug-in/editor).
Clojure will probably never storm the JVM world because people are prejudiced against LISP languages. For me, it’s actually easier to write right now but I remember that in the beginning, it wasn’t easy (Parinfer helped – a lot – more than Paredit, to be honest).
Another problem I see with Clojure (and specially with ClojureScript) is what I like to call the “isolated genius”. As an example, functions in Clojure are not interchangeable with Java anonymous functions/closures (added in recent JVMs); support for interop works well, sometimes, but not always (it’s hard to make a Spring app with Clojure for example, because of annotations and other stuff).
The problem is actually way worse in ClojureScript. There’s no easy support to integrate with the whole Javascript world, so writting Solid.JS, Svelte, etc is not easy or needs some non-trivial wrapping; no support for JS classes, template strings, etc also complicates adoption.
I think it’s hard to sell Clojure as a language for people that are not willing to learn (and there’s a lot of people like that) – that’s probably why Kotlin exists and it’s popular (because it is closer to Java than Scala, for example). I don’t honestly see a way around this, but I know that accepting that these other practices exist in the JVM / JS world (annotations, the whole bundler/transpiler/babel stuff in JS) and somehow add them to Clojure(Script) via macros or some helpers might help adoption.
(I imagine a world where I can pick up a Spring Boot, VertX app in Java and somehow add Clojure code to it, and start to interactive develop the migration from one language to another without needing to wrap stuff, have multiple compilation steps, etc…).
Jiri knesl: To the point it even broke my old TDD workflow . I had to re-train myself to write better tests, because I was starting to neglect my testing (I think I found a sweet spot now, but I’m studying a way to have an even sweeter spot with my plug-in/editor).
Would you mind to elaborate on this?
Mauricio Szabo: Sure – about my TDD workflow, in Ruby I used to make a test so that I could quickly run some code fragment. In Clojure, I can just… run the code . I don’t actually need a test because my data, my parameters, everything is still in the REPL, and I’m connected to my app, so my “seed data” is already there. I ended up writing a lot of code without writing the tests first. Which is kinda fine if you remember to write the test later; unfortunately, my experience is that if I write the test later, I might miss some branch, some special treatment, etc that I captured in the REPL. Fast-forward to 2 hours later, when I have to add a new case for that specific function, see a very complicated piece of code, refactor it thinking “what I was doing?” and then things break in the app.
Then, I remember ah, this very complicated code is because there’s an edge-case indeed.
Another thing is that we usually don’t do the second step of testing: writing things and see it fail. It’s probably the most misunderstood concept in automated testing. My experience is that experiencing the test failing means we’re indeed testing the right thing – how many times I wrote a test, ran it, and it passed when it shouldn’t… then I figured I was not testing the right thing.
Classical example is authorization – suppose you want to return a 404 error when the user doesn’t have access. If you write a test, and it immediately passes, you’re probably using the wrong URL, for example.
(and that is even worse if the code is already written and you’re just covering with tests – you can assume that the test is passing because the code is working, and even if the code is indeed working, you might be testing the wrong thing).
The problem is actually way worse in ClojureScript. There’s no easy support to integrate with the whole Javascript world, so writting Solid.JS, Svelte, etc is not easy or needs some non-trivial wrapping; no support for JS classes, template strings, etc also complicates adoption.
Yes, but isn’t it the price we pay for Clojure-like experience (mainly persistent data structures)?
Of course, you could just build a lisp that compiles to JS, but Clojure is not just a lisp. It’s a runtime too and this runtime is built on different assumptions than JavaScript is.
Mauricio Szabo: As for this one, more or less. We could have proxy or defclass or gen-class for Javascript too – Shadow, for example, have support for JS classes and template strings.
It should also be possible to put the ClojureScript compiler “in the middle” of JS tool – like, compile the ClojureScript code, generate something intermediate (maybe JSX, maybe even Svelte) and then feed that into another tool, generating a final JS in the process, with the code to hot-reload the runtime.
By the way, this is kinda possible with Shadow-CLJS hooks but maybe don’t generalize well enough…
src/babble/core.clj · trying-to-use-hooks · Maurício Szabo / babble · GitLab
Jiri Knesl: Better interoperability might help with writing JS code in Lisp. But how could you retain the value of STM while interacting with mutable data structures that are the default in JS ecosystem?
Mauricio Szabo: I don’t think ClojureScript needs to embrace the native data structures – the interop with the mutable stuff in JS is honestly good in my experience. It’s more offer some way to integrate with the compilers and bundlers, support full JS syntax (and have a way to emit JSX maybe) and to import arbitrary Javascript.
As of today, we can’t emit class or function*, we don’t have async nor await, we can’t use correctly things like StyledComponents, and that’s just talking about unsupported syntax… we also have unsupported Javascript that can’t be compiled into a single bundle because Closure Compiler doesn’t support it.
That being said, I’m putting a lot of hope in Cherry – as soon as it have a REPL (and maybe hot reload) I really want to drive it with some ideas.
Jiri Knesl: Today, jQuery 4 came out. One of my colleagues was joking that a combo of cherry+jquery+hiccup is inevitable framework someone will build. And also, HTMX is getting quite a hype.
And when you look at ClojureScript, it’s mainly a land of React wrappers.
How does a future of frameworks using Clojure on frontend look like to you?
Mauricio Szabo: I don’t have many experiences with Clojure on frontend, honestly, so I don’t know. And yes, I agree that it’s a land of React wrappers – I actually wanted to test Membrane and Arborist, but I needed a way to interop with some JS libraries and React was the best bet.
But even now, on Chlorine, I’m even rethinking React (Reagent in this case) – I figured out I “defaulted to React” without a real need, and things are harder than they needed to be.
By the way, if I might add, even with all these downsides (in my point of view, at least) ClojureScript is still my “go-to” choice to write something in Javascript. The ability to use the REPL and have hot-reload capabilities inside a Javascript environment (no matter how hostile – I got it working while making a NeoVim plug-in for example!) is insane, specially when we consider that in Javascript we usually have a lot of internal state, mutability, transformations happening in the UI, etc.
Jiri Knesl: Have you tried using Cherry in any projects already? How’s the experience different from Cljs?
Mauricio Szabo: So, I tried a little bit, it’s close to CLJS with some exceptions (some bugs I had that are fixed by now). It’s interesting because I could use some stuff that needs a lot of hacks in Shadow, but my workflow is hugely dependent on the REPL (and Chery doesn’t have a REPL yet – Squint does, but I don’t know how powerful it is) and nor does it have a hot-reload workflow, so I ended up staying in ClojureScript only for now
Babble is not yet battle-tested, but I want to try to a project too – maybe we can exchange experiences later?
Gustavo Valente: One thing I want to ask is about AI. How are you seen all the AI hype and specifically in regarding with Clojure and Clojurescript, what do you think that Clojure/Clojurescript could benefit from it?
Mauricio Szabo: Well, who haven’t right? For now, I feel it’s a hype indeed, but it worries me to be honest – not that it will replace my job, but that it will normalize bad code.
At the same time… I fell bad code is already normalized so maybe I’m just nitpicking.
For Clojure and ClojureScript, specifically, I don’t know. Not in the direction that AI is going.
For multiple languages, I feel that these LLMs could be used as a “support level 1” or even a “documentation layer” – I don’t know how possible this is, or even if it is possible, but the idea could be to train the AI with some organizational repository, or a couple of projects, and be able to ask AI things like “I want to authenticate against OAuth, which function do I use?”
Another thing I wanted was to not drive AI via comments, but drive via tests – write the test, and ask to generate the implementation. I feel it’s less prone to errors this way, honestly. The opposite (what people are doing right now – write the tests when you already have the code) is, in my opinion, one of the worst possible usage of LLMs – we already have bad tests in the wild, tests that check internal state, that test the wrong thing, are needlessly complicated or hard to read. Automating the writing of these bad tests is definitely no the right path – *specially because* it’ll normalize another bad practice that I see happening a lot – when someone wants to change a behavior, they will change the code, see all tests that are failing, and deleting/commenting them and writing a new one.
In this sense, tests are basically meaningless. Instead of looking at failures to see if they are valid, everything is just thrown away. Now imagine if we have a way to automate this process?
Finally, the direction I wanted to see AI going for Clojure[Script] (and LISPs in general) – to write code in a meaningful way. Like, write an implementation that works using the inputs the actual functions that we have in the language. Things like, if I ask for a tool to concatenate strings, the AI knows which functions operate on strings, then tries to compose a function that actually does what I want – then it starts a shrink process, to generate the smallest possible solution that satisfies what I do.
I remember when I studied a little bit about genetic algorithms, there was something related to that – to generate “LISP forms” that operated on the parameters and then tried to get the best solution. It worked, but to make simple things like a math problem it took a long time and it usually didn’t get it right. I don’t know if that’s possible today, with all the advancements and such.
Gustavo Valente: And editors… Tell us about your journey into working to build an editor and WHY?? Yeah, I am a big fan of emacs, and I was wondering why not extend it instead build other one? Tell us a bit of Pulsar, main features that don’t have in other editors, etc.
Mauricio Szabo: Well, it’s a loong story. But it starts with NeoVIM and my work on making plug-ins for it.
Then, seeing the insanity that is to do it, and trying Sublime. But again, the whole plug-in world in Sublime is insane – it’s in Python, and if Python doesn’t have a proper, built-in module support, imagine that inside an editor?
So I tried Atom. And honestly, I loved it. It was slow, had a horrible typing lag, but the plug-in system was simply amazing so I made my own collection of plug-ins, to the point I decided to use it for Clojure too – first by helping the author of the old Clojure plug-in proto-repl, then adding my own config on top of that, and finally where I am today – with Chlorine.
And then, Microsoft happened.
When they bought GitHub, we all feared from the future of Atom, but fortunately, the future GitHub’s CEO spoke that they would keep Atom.
Which, of course, was a lie. Atom stopped gaining features and only the most trivial of bugs were fixed. Still, it was a good editor for me, but it started to show signs of being abandoned. So I decided to scrap what was still useful of Atom and integrate with some newer tools, and created a new project called Saturn – initially, the idea was to support the Atom API and the VSCode one (a bold decision, I know).
But then, in December/2022, Atom was officially dead. The idea to keep an Atom API was now in check, because no more plug-ins would be added to it, and Chlorine also had a VSCode version. My initial idea was to implement only a VSCode API, but add some “extension points” so that I could have an improved “hackable” experience.
Just for fun, I tried to ping the atom-community discord, and some people showed interest in keeping a fork of Atom. One was already working on reverse-engineering the backend so that package installation would still work.
That gave me some hope, so we made some polls for a new name, tried some logos, worked on some rebranding, but because we had huge disagreements on the direction atom-community was heading (basically, bundle some packages that we didn’t agree, disagreeing the name that won the poll, and also because they wanted to migrate everything to Typescript instead of keeping only Javascript) we decided to make a new fork, and Pulsar was officially born.
So it’s not like I made something from scratch, mostly I helped to save Atom from total extinction .
As for why not use Emacs – I don’t really like, or understand, Emacs. I always seem to become stuck on some intermediate keybinding, mode, or whatever that I don’t know how to exit, so in a way it feels that I’m always fighting the editor. There are some good distributions like Doom Emacs or Spacemacs but they are heavily opinionated in my opinion. Also, Javascript – I feel the async model of Javascript works really well for plug-ins in an editor. The fact that creating UI elements is literally just Javascript + CSS + HTML is a huge win, and also means I can re-use anything that exists for the web already without any “conversion layer”.
For the things that Pulsar have that other editors lack, well, to be insanely customizable and hackable is one. UI can be changed a lot (because it’s all HTML + CSS), and the plug-ins API is insanely good – you can basically change the UI in any way you want (to the risk of breaking the editor, sure) and you have extension points that allow you to put HTML elements in almost any position.
A simple example are inline and block decorations – in any point in the editor, one can add an inline, or a block, and include HTML on it. Any HTML – generated via some string, or via DOM APIs.
Like this one, that generates a better review of tests that fail.
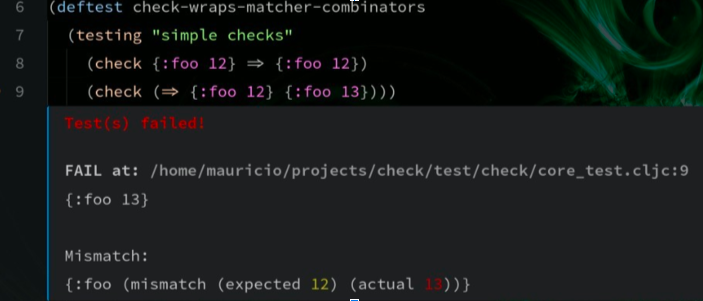
VSCode, for example, is a walled garden. You do have some APIs that you can extend, but you can only do that in the terms they support. There are some inline/block decorations, but they only accept text or markdown, or only appear when hovering, etc. They are fine-crafted to customize the functionality that VSCode already have, not to add a whole different thing.
And finally, packages. The way a package can communicate with the other in Pulsar is simply mind-blowing for me: we have what is called a “Service”.
A Service exposes an API, and it’s composed by providers and consumers. A simple example is Autocomplete – bundled with Pulsar is a package called autocomplete-plus that consumes the autocomplete service. Then you have multiple providers of that service: there’s a built-in that checks what’s in your editor, and suggests words for it, scored by how close they are; there’s Chlorine, my own plug-in, that provides suggestions using runtime information that comes from the REPL; and there’s LSP, that provides suggestions based at the LSP protocol.
If one doesn’t like the built-in autocomplete, that person can disable the built-in package and install a different package that provides the same service. And everything magically works!
So even considering that autocomplete is built-in, it’s customizable – and in a way that doesn’t need any change from the providers of suggestions. That is actually huge, and I’m yet to see some other editor that can have the same level of customization without needing to understand the internals of the codebase.
Jiri Knesl: BTW, what are you working on right now?
Mauricio Szabo: I’m heavily focused on getting a full refactor of Chlorine right now.
The original idea of Chlorine was to offer a great plug-in for the Atom editor written in ClojureScript, and support for Socket-REPL. The second idea was, frankly, a mistake – socket-repl never got any traction, not even with the prepl layer, while nREPL evolved a lot. Eventually, most of my Chlorine work was just to fix Socket REPL stuff, and even then, the experience was sub-optimal.
So now I’m fully committed to nREPL and the Shadow Remote API, so I have some very interesting stuff that’s supported – for example, with ClojureScript Chlorine now supports selecting the JS environment that it’ll run the code. It also displays compilation errors and warnings, and automatically resolves promises.
What I really want to add is some “tracing support” – like FlowStorm, for example – where I can evaluate a code (or just start the trace and interact with the app for a while) and see what happened, which functions were called, parameters, returns, etc.
And also adapt some data-science library for custom visualizations. I’m interested in Kindly, especially the concept they have of “advisors” – one thing that I really want is to somehow customize the way I can render EDN in the editor.
One possible case is – rendering a map with lots of keys – maybe more than 20, more than 50 – and “prioritizing” some keys over others (like, for example, if I’m developing some code that handles personal information, I might probably want to focus on :id, :name, maybe :role or fields like that).
Jiri Knesl: Fantastic, thank you.
I was always curious, why have you picked Atom to work on?
Mauricio Szabo: Mostly, because it was “already there”. I was already an user of Atom, the community was starting to get organized to keep the editor, so it gave me the push to keep the editor.
But also, because of the capabilities of the editor to be friendly and to be almost infinitely customizable.
One example that I always mention is Autocomplete. While it is a core element of the editor, nothing in the core of the editor implements autocomplete – it’s a plug-in. A core plug-in, sure, but still a plug-in.
Now, Atom (and Pulsar, by definition) have this concept called “Services”. Basically, any plug-in – be it a “core” plug-in or not – can define its own API. The API is simple: a plug-in can define either that it’s a “consumer” or a “producer” of the API – think like “client” and “server”, more or less.
So, autocomplete in Atom/Pulsar is a “consumer” – it defines an API so that other plug-ins can contribute with “suggestions”. The API is literally some JS object with one to four methods (one is mandatory – the one that actually offers suggestions – and the others are optional).
And here is the thing that excites me the most: rethink some old ideas.
VSCode, as I said, it’s a “walled garden” – it is completely opinionated on how things should work.
I don’t like this approach because I feel it limits how things should work. The LSP protocol, for example, is really tied to the idea of “static analysis” of the code, to “intellisense” and other stuff. Calva does an amazing job re-thinking how some of these “pre-defined extensions” can be used to show code, but I feel we can go further. I feel we can try to walk “the road not walked”, like for example, Smalltalk.
To give a concrete example/idea with autocomplete: we currently think of Autocomplete as a way to write something in text, get some suggestion, select the suggestion, and get that filled for us. Usually we filter the suggestion using parts of the word, or fuzzy-finding, etc – like, if I type us, it’ll try to suggest me use
Now, imagine we could do something different. Suppose we could deprecate some function/variable and put a doc saying “this is deprecated, use require with refer instead”. And then autocomplete could suggest, in place of use, require – and add a snippet for us with that info.
Or, jumping the AI hype, we could trigger the autocomplete, and when we chose a suggestion, we could open a context menu with some additional suggestions on how you probably would use that specific code with the variables you have right now.
On other editors, this need a lot of work and if the editor’s author doesn’t agree with you, you’re out of luck.
With Atom/Pulsar, you don’t need anyone’s permission – you can literally disable the core autocomplete, and write your own, implementing the same API, and inform (in the package.json) that it’s a consumer of the autocomplete service.
And the magical thing is that it’ll simply work – every plug-in that contributes to suggestions will still work, be it LSP of some REPL-connected plug-in like Chlorine, etc.
Also, besides what people say, Atom was slow in the beginning, but the latest version that was published (1.60) was not slower than VSCode, for example – and it did run in Electron 9, which means Node 10, a very old version of both Chromium and Javascript.
As for me, I’m using now an experimental branch with Electron 27 (a version from 12 days ago), and it does speed up things quite a bit (considering all the upgrades to Node, Chromium, etc). The simple fact that Pulsar is even running on this latest Electron is a miracle by itself, considering all the breaking changes I had to fight to make it work.
Also, on a tangent, I considered for a long time to try and speed up my own editor Saturn when the end of Atom was announced.
Initially, the idea was to support both the Atom and the VSCode APIs, but after the announcement I though about supporting only the VSCode API, but somehow add some “extension points” to it.
For example – CodeLens. In VSCode, anytime you want you can have some text between lines in the editor, and if you click on these lines, some command can be called.
The way that it works is – you register a “Code Lens Provider” (nothing remotely related to the idea of Providers in Pulsar) and you return a Command. The command will have a “title” property that will be displayed. That’s it.
In Pulsar, we have “block decorations”. It’s insanely more powerful – you can have arbitrary HTML, so you can implement this “Code Lens” or you can do other stuff, like show the evaluation results, show a tree, plot something, render a chessboard… anything, really.
If you add a link, or a button, you can register that if you click on it, you can evaluate arbitrary node commands – including, for example, calling the Atom API, replacing text, etc. Again, incredibly powerful.
To make this work in my Saturn project, the idea I had was to implement CodeLens but allow people to return arbitrary HTML elements instead of a “command” – that basically would give me the same behavior as Atom, but would still be compatible with VSCode.
To be fair, this idea is not 100% dead – I’m trying to implement a VSCode compatibility layer in Pulsar, and I do want to try and implement this “extended API”. But the honest truth is simply that the VSCode API is too big, it’s a moving target, and there are some undocumented/internal stuff that I found out trying to make some VSCode plug-ins work…
Jiri Knesl: Let’s move on. If you weren’t working in Clojure, what language/s would you like to learn?
Mauricio Szabo: I want to learn so many languages
I really want to try something with gToolkit (Smalltalk). It sounds really interesting and it seems quite like what I wanted to achieve with Chlorine.
I am a little interested in Rust too, but I’ve been delaying my studies because I don’t really identify myself that much static languages, but I kinda want to experiment with WASM and Rust seems the “safe bet” for now.
(Hopefully Jank can also be used in the future).
Jiri Knesl: Speaking of SmallTalk, do you consider SmallTalk working with images instead of files an advantage, or the opposite?
Mauricio Szabo: Yeah, it’s complicated. On one side, I would love to not depend on text files, because I do feel they are limiting (usually, we are interested in fragments of the files – for example: what does this specific function does, which are the functions it depends on, what are the testcases that exercise this specific function I’m working now).
I feel we could gain a lot if, instead of having a huge file open with what we’re working and other unrelated stuff above and below, we could have the specific function/method/class we’re working and then everything it depends around it – maybe in a star-like pattern, something like this.
At the same time, everything breaks down if we don’t use files. Smalltalk’s images need to be edited with the tools that are already inside the image – so no “emacs”, no “vim”, no “Pulsar” – not even “vim mode emulation” for example.
Git integration (at least the one I tried) is horribly complicated and it risks doing things that we don’t want to do (it’s semi-automated, and I don’t think a good fit for git is to automate commits for example); at the same time, seems weird to use git as a version control mechanism, because we’re not working with files.
Finally – all these ideas I had (the functions being around in a star-like pattern, editing individual fragments, etc) they kinda exist in Smalltalk, but they are far from being straightforward. It’s not much better than using splits in the text editor in my experience, so while ST does use images, I don’t think it’s a better experience.
So, images could be a good thing, if implemented correctly, but the benefits need to vastly outweigh the paradigm shift, and I honestly don’t think they do in Smalltalk (for code editing).
Now, for running code, that’s a different story.
If we could persist exceptions, for example, with all the bindings we had around the exception, the stacktrace (like, the real stacktrace, a live, breathing object in the image, not a text representation), or have a good tracing information (querying the VM to see live objects, interact with the VM by doing that, etc – imagine, for example, if I have two function that do the same thing – one really fast but it takes a lot of memory, and the other slower but it’s cheap; I could query the VM to see if there’s too many “live” objects,, or how many threads are running right now, etc, and decide which function to call), that could be amazing and open up a new kind of execution model.
Jiri Knesl: From my point of view, image based apps are awesome when you are one person, keep all changes in your head. In the early stage of hacking the app, it might work.
For a team, having text based project, code review and keeping track with changes is much easier.
BTW, have you heard the narrative about genius Lisp developer who wants to build everything himself? I think this might be true for Smalltalk.
Mauricio Szabo: Yeah, I don’t know if that’s a failure with the idea of images or if it’s a limitation of tools that we have.
For example, we don’t have a standard that defines what an image is – where we do have standards for defining text.
Even in the same language, images are not compatible between implementations – sometimes even between versions!
I actually have a question: what do you folks think about the future of ClojureScript? Asking because I’m seeing people complaining (rightfully so) about some friction between CLJS and JS, and the lack of tooling (or worse experience with CLJS tools), and the recent boom of Typescript.
Jiri Knesl: I see people really speaking about just two Clojure in JS implementations in Flexiana. The classic Cljs with re-frame and Reagent, which is something we still teach everyone in Flexiana.
And then there’s a lot of interest in ClojureDart with Flutter as an alternative. I suppose for mobile apps we would use it instead of ReactNative. Flutter can be used for WebApps too (which we haven’t tried yet) so I count it as a second option.
Also, to be honest, we have successfully used HTMX a couple of times and moved all logic to backend. For many use cases, that’s great. SPAs are overused. That’s what I see a lot.
When you look at our framework, it’s all backend. We have used re-frame and Reagent, React.js (with or without next.js) and HTMX. That’s what we focus on the most as of now.
While you are waiting for the next Clojure Corner you can read our past Corner with Yehonathan Sharvit.





